Fully Homomorphic Encryption Part Three: Three Strawmans for the FHE Scheme
02 Jul 2020In my previous post, I went over how Lattice-based crypto works, as well as what Learning With Error (LWE) Problem is. In the end, we looked at how Regev Encryption works by putting the LWE problem together with an encryption scheme.
Hopefully, everyone should have a pretty solid understanding about these fundamental building blocks. Now we are finally ready to battle the archnemesis - building the actual FHE scheme.
Recap
Before we begin, let’s do a quick recap of what we have learned before.
Learning With Error (LWE) Problem
In the last post, we went over what the LWE problem is and why it matters.
Basically, LWE defines some large matrix $ A $, and a hidden vector $ s $. We are only given $ A $, and the product with error ($ As + e $), and the task is to recover the hidden vector $ s $ from the two inputs. Later, we are also given the Decisional LWE (DLWE) version of the problem, which asks us to distinguish between the LWE problem instance ($ A, As + e $) and just a uniformly sampled random matrix. Both SLWE and DLWE are conjectured to be hard.
To better understand why DLWE is hard, here is a useful diagram that we can look at:

By looking at the top of the diagram, we can see how we constuct the product with error term $ As + e $. Notice that the dimensions match nicely. Now, we put $ A $ and $ As + e $ together (as shown on the bottom). Since SLWE is conjectured to be hard, we cannot really recover $ s $ from $ As + e $, and it will just look like some random values to us. Therefore, our view of the problem $ A, As + e $ is computationally equivalent to a $ m \times n + 1 $ matrix with uniformly sampled random values in $ \mathbb{Z}_q $.
Regev Encryption
Last time, we also took a look at how Regev Encryption works.
Regev Encryption basically maps the value of a bit (0 or 1) onto two sides of a ring finite field. Then it applies the LWE product with error $ As + e $ onto the value. Because of the hardness of DLWE, the product with error term $ As + e $ is indistinguishable from a randomly sampled vector $ v $. Therefore, applying the LWE product with error onto the original value is equivalent to applying an One-Time-Pad onto the original value, therefore guaranteeing its security.
Upon decryption, we use the knowledge of the secret vector $s $ to remove the One-Time-Pad. However, since the original product with error also carries an error term, our result is also offsetted by this error term.

The diagram above visualizes how the error term will affect the decrypted result.
We see that the original value is either going to be 0 or $ q/2 $. Once we remove the LWE OTP from the ciphertext, we are left with some errors that will shift the value up or down the ring. However, as long as the absolute value of the error does not exceed $ q/4 $, it will be safe for us because the resulted value will always stay on the same side of the ring.
Therefore, keeping the error bound under $ q/4 $ will guarantee the decryption to succeed. This is also the reason why we enforce $ q/4 > mB $ in our encryption parameter setup.
Fully Homomorphic Encryption
Finally, let’s review the definition of FHE once again!

We can basically treat the FHE problem as if an user has some secret input $ x $ and would like the cloud to obliviously compute function $ f(\cdot) $ for him.
First, the user will use an FHE scheme to encrypt his secret input and send $ Enc(x) $ to the cloud. Then, the cloud will use the FHE algorithms to apply function $ f $ on the original ciphertext and obtain $ Enc(f(x)) $. Finally, the user decrypts the encrypted result and obtains $ f(x) $.
The formal definition of a valid FHE scheme contains 4 fundamental algorithms:
- $ KeyGen(1^\lambda) \rightarrow sk $: The key generation algorithm that generates the secret key for this instance.
- $ Enc(sk, \mu \in {0,1}) \rightarrow ct $: The encryption algorithm that encrypts a single bit $ \mu $.
- $ Dec(sk, \mu \in {0, 1}) \rightarrow \mu $: The decryption algorithm that recovers $ \mu $ from the ciphertext.
- $ Eval(F, ct_1, …, ct_l) \rightarrow \tilde{ct} $: The evaluation algorithm that evaluates arbitrary functionality $ F $ over a set of $ l $ ciphertexts.
Alongside the four algorithms, a valid FHE scheme also needs to satisfy 3 properties:
- Correctness: The scheme needs to be correct so that after evaluation, the ciphertext can be successfully converted back to the intended plaintext.
- Semantic Security: The ciphertext produced by this encryption scheme needs to be indistinguishable. This defends the scheme against eavesdroppers.
- Compactness: The output length of the $ Eval $ algorithm needs to be small and independent from the size of the evaluated functionality $ F $.
Levels of FHE
We have also learned about the 4 different levels of FHE:
- Partially Homomorphic Encryption: This is for schemes that are either additively or multiplicatively homomorphic. For example, RSA and ElGamal.
- Somewhat Homomorphic Encryption: This is for schemes that are PHE first and shows very weak traits of the other missing homomorphic property. For example, ElGamal in Pairing-friendly groups.
- Leveled Fully Homomorphic Encryption: This is for schemes that are already fully homomorphic, but impose a complexity upper bound $ L $ such that the circuit evaluated for the functionality $ F $ must be within the boundary. Ususally the bound $ L $ is pretty low.
- Fully Homomorphic Encryption: This is for schemes that are trully fully homomorphic. There is no complexity upper bounds and thus can evaluate any arbitrary functionalities.
Last time we also talked about that with this notion of Bootstrapping introduced by Gentry in 2009, we can turn suitable Leveled FHE schemes into real FHE schemes. The GSW scheme is indeed built up from this way.
Since I promised you that we will go over how GSW works in detail, today we will be putting all these building blocks together and build up our first Leveled FHE Scheme. Once this is done, we’ll talk about applying Bootstrapping (presumably in the next post).
Most of these materials are covered in detail in the previous two posts, as here is just a brief recap and emphasis of these key concepts. If you are still uncomfortable with these concepts, feel free to return to the previous posts again and check them out.

Constructing a Leveled FHE Scheme
That was a quick recap session for the stuff that we learned so far. Now let’s construct a Leveled FHE scheme!
In order to achieve LFHE, we will be building it up in three steps. Namely, we will talk about 3 straw man protocols that gradually build up to our final LFHE system.
Long story short. Let’s begin.
Straw man #1: Eigenvalue and Eigenvectors
According to the definition, if we have a scheme that can successfully evaluate addition and multiplication using the $ Eval $ algorithm, that scheme is fully homomorphic.
I hereby propose our first construction of a FHE scheme - using very simple linear algebra.
KeyGen
The $ KeyGen $ algorithm is very simple: we simply randomly select a vector $ \vec{s} $, and that will be our secret key.
Encryption
$ Enc(\vec{s}, \mu) \rightarrow C $: For encryption of message $ \mu $ (a multi-bit number), we will simply output a matrix $ C $ such that: \(C \cdot \vec{s} = \mu \cdot \vec{s}\) If you know linear algebra, you will instantly recognize this expression! Namely, $ \vec{s} $ is the eigenvector of the matrix $ C $, and $ \mu $ is the eigenvalue. Basically the encryption algorithm becomes - find a matrix $ C $ such that it has eigenvector $ \vec{s} $ and eigenvalue $ \mu $.
Decryption
$ Dec(\vec{s}, C) $: Decryption is very easy. We basically multiply $ C $ with $ \vec{s} $ and obtain a multiple of the original vector $ \vec{s} $. All we need to do is to find the correct multiplier $ \mu $ such that $ C \cdot \vec{s} = \mu \cdot \vec{s} $.
Evaluation
Now let’s see how the $ Eval $ algorithm works. Namely, to get FHE, we just need to get addition and multiplication functionalities work:
$ Eval(+, C_1, C_2) $: In order to evaluate addition of two ciphertexts, we can simply output $ \tilde{C} \leftarrow C_1 + C_2 $. The correctness is also easy to verify: \((C_1 + C_2) \cdot \vec{s} = C_1 \cdot \vec{s} + C_2 \cdot \vec{s} = \mu_1 \cdot \vec{s} + \mu_2 \cdot \vec{s} = (\mu_1 + \mu_2) \cdot \vec{s}\) $ Eval(\times, C_1, C_2) $: To evaluate multiplication of two ciphertexts, we can also easily output $\tilde{C} \leftarrow C_1 \cdot C_2$. Again, we can see the correctness of multiplication as well: \((C_1 \cdot C_2) \cdot \vec{s} = C_1 \cdot (C_2 \cdot \vec{s}) = C_1 \cdot \mu_2 \cdot \vec{s} = \mu_2 \cdot C_1 \cdot \vec{s} = \mu_2 \cdot \mu_1 \cdot \vec{s} = (\mu_1 \cdot \mu_2) \cdot \vec{s}\) Surprisingly, this scheme is capable of evaluating both additions and multiplications!
Problem
If the first try would worked, we would be so happy and I can gracefully end my post here. Although this scheme is perfect at both additive and multiplicative homomorphism, due to some very unfortunate reasons, this perfectly homomorphic construction is invalid.
The reason why this construction is not a valid FHE scheme is due to a glaring flaw: Given matrix $ C $, it is really easy to find its eigenvector $ \vec{s} $ and eigenvalue $ \mu $! Although this scheme is perfect, it also has no hardness at all - so we can barely call it an “encryption” scheme.
In fact, cracking this “encryption” scheme is as simple as using Gaussian Elimination to easily recover $ \vec{s} $ and $ \mu $.
So how do we keep this great scheme yet make it harder? We do exactly the same thing as we do to system of linear equations: Add noise.
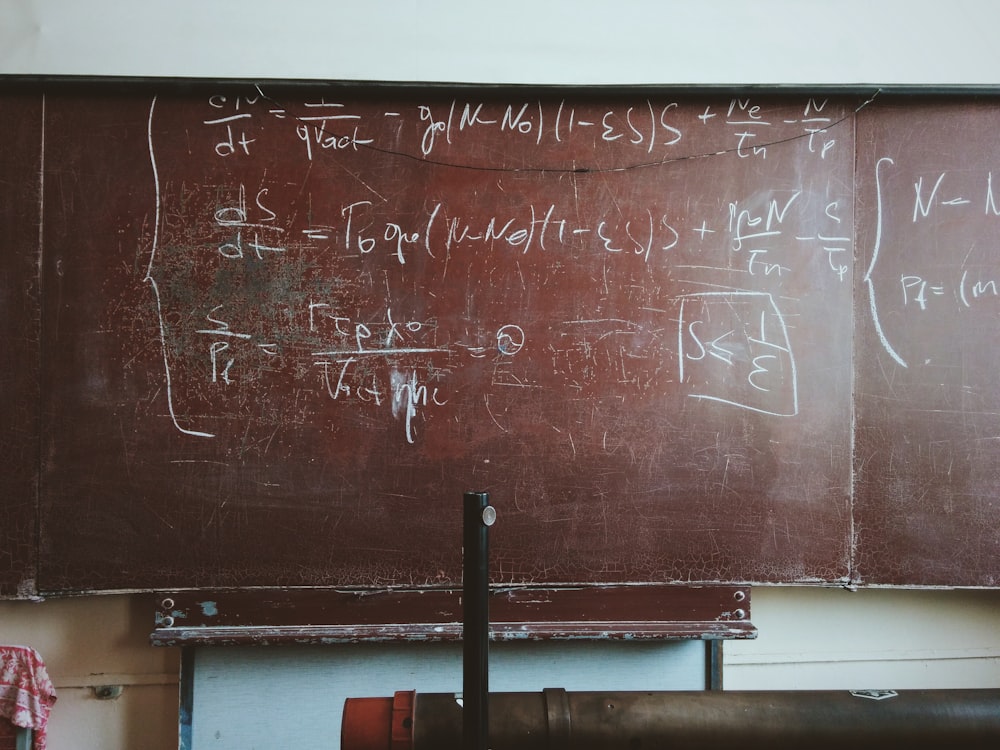
Straw man #2: Add More Noise
Now, just like how we converted system of linear equations to LWE, let’s add some noise to our original construction. Generally, we would be getting some relation like this: \(C \cdot \vec{s} = \mu \cdot \vec{s} + \vec{e}\) Notice that this relation is almost the same as the previous construction except for that we introduced an additional error noise term $ \vec{e} $ to the equation.
Now, let’s formally define our second noisy construction.
KeyGen
$ KeyGen(1^\lambda) $: We will formally define the key generation algorithm here. First, we will sample a random vector $ \tilde{s} \in \mathbb{Z}_q^{n-1} $. Then, we vertically append a -1 to $ \tilde{s} $ to obtain $ \vec{s} \leftarrow \begin{pmatrix}\tilde{s}\-1\end{pmatrix} $. We output both $ \tilde{s}, \vec{s} $ as the secret key.
Encryption
$ Enc(\tilde{s}, \mu \in {0, 1}) $: We will use single bit encryption again for this time. To encrypt a bit $ \mu $, we will need to first construct an LWE instance.
First, we randomly sample matrix $ A \stackrel{R}{\leftarrow} \mathbb{Z}_q^{n \times (n-1)} $. We also sample the error vector $ \vec{e} \stackrel{R}{\leftarrow} x_B^n $.
Then, we will output the ciphertext $ C $: \(C = \underbrace{(A, A \cdot \tilde{s} + \vec{e})}_\text{LWE Instance} + \overbrace{\mu \cdot I_n}^\text{message} \in \mathbb{Z}_q^{n \times n}\) Here $ I_n $ is the identity matrix with dimension $ n \times n $.
Notice that on the left hand side of the expression, we are concatenating matrix $ A $ and vector $ A\tilde{s} + \vec{e} $ together into a square matrix with dimension $ n \times n $. Due to the DLWE assumption mentioned in the beginning, we can treat this as a random One-Time-Pad to the actual encrypted value $ \mu \cdot I_n $ on the right side.
Decryption
$ Dec(\vec{s}, C) $: Now when we try to decrypt the ciphertext $ C $. We will simply compute $ C \cdot \vec{s} $ and then output: \(\text{output: } \begin{cases} 0, & \text{if } \mid\mid C \cdot \vec{s} \mid\mid \text{ is small}\\ 1, & \text{otherwise} \end{cases}\) The correctnesss proof for the decryption is also pretty straight-forward. Let’s expand the multiplication $ C \cdot \vec{s} $: \(\begin{align*} C \cdot \vec{s} &= ((A, A \cdot \tilde{s} + \vec{e}) + \mu \cdot I_n) \cdot \vec{s}\\ &= (A, A \cdot \tilde{s} + \vec{e}) \cdot \vec{s} + \mu \cdot I_n \cdot \vec{s}\\ &= A \cdot \tilde{s} - (A \cdot \tilde{s} + \vec{e}) + \mu \cdot \vec{s}\\ &= \mu \cdot \vec{s} - \vec{e} \end{align*}\) Since vector $ \vec{s} $ is simply the original vector $ \tilde{s} $ stacked on top of a $ -1 $, multiplying $ (A, A \cdot \tilde{s} + \vec{e}) $ and $ \vec{s} $ is equivalent of multiplying matrix $ A $ by vector $ \tilde{s} $ and then subtract $ A \cdot \tilde{s} + \vec{e} $ from it. In the end, we get something that is similar to the relation that we started with. Since the error is sampled randomly with an upper bound on its absolute value, we can safely flip the minus sign and the equation will still hold.
Since this relation $ C \cdot \vec{s} = \mu \cdot \vec{s} \pm \vec{e} $ is very similar to the original eigenvector/eigenvalue relation. We ususally call $ \vec{s} $ an approximate eigenvector of matrix $ C $.
Evaluation
So far so good. Now let’s see how to evaluate addition and multiplication on this new system.
$ Eval(+, C_1, C_2) \rightarrow C_1 + C_2 $: Evaluating addition is the same as before - we just add the two ciphertexts together. If we try to decrypt the addition result, it will look like the following: \(\begin{align*} (C_1 + C_2) \cdot \vec{s} &= C_1 \cdot \vec{s} + C_2 \cdot \vec{s}\\ &= \mu_1 \cdot \vec{s} + \vec{e}_1 + \mu_2 \cdot \vec{s} + \vec{e}_2\\ &= (\mu_1 + \mu_2) \cdot \vec{s} + \underbrace{(\vec{e}_1 + \vec{e}_2)}_\text{small error term} \end{align*}\) We see that when we add $ C_1 $ and $ C_2 $ together, we can efficiently obtain the encryption of $ \mu_1 + \mu_2 $, with a small caveat that the error term for this encryption now is $ \vec{e}_1 + \vec{e}_2 $. However, since we know that the error vectors are small and sampled from a bounded distribution $ x_B $, we can safely treat this as a manageable small term and there’s no problem at all.
$ Eval(\times, C_1, C_2) \rightarrow C_1 \cdot C_2 $: We follow the original construction and multiply the two ciphertext together to evaluate multiplication. Expanding the decryption of a multiplication result gives us: \(\begin{align*} (C_1 \cdot C_2) \cdot \vec{s} &= C_1 \cdot (C_2 \cdot \vec{s})\\ &= C_1 \cdot (\mu_2 \cdot \vec{s} + \vec{e}_2)\\ &= \mu_2 \cdot C_1 \cdot \vec{s} + C_1 \cdot \vec{e}_2\\ &= \underbrace{\mu_1 \cdot \mu_2 \cdot \vec{s}}_\text{Result} + \underbrace{\mu_2 \cdot \vec{e}_1}_\text{small error term} + \underbrace{C_1 \cdot \vec{e}_2}_\text{large error term!} \end{align*}\) From the expansion, we see that we do obtain the multiplication of the original plaintexts, plus a small error term $ \mu_2 \cdot \vec{e}_1 $. This term is small because our plaintext $ \mu $ is binary, and the error sampling in the vector $ \vec{e} $ are all bounded by a small $ B $. However, the final term $ C_1 \cdot \vec{e}_2 $ is really bad. As the values in $ C_1 $ are not bounded by any distribution are directly sampled from the finite field $ \mathbb{Z}_q $, its product with the error product is also unbounded! This means that the last term can easily get huge and blow up the noise tolerance in our scheme.
Problem
Adding noise into our original construct does help with semantic security, because now it’s computationally hard to recover the approximate eigenvector and eigenvalue given the matrix $ C $. However, this additional noise also destroys our perfect homomorphism.
While the noise term when evaluating addition is ok, multiplication is the big problem here. We currently have this $ C_1 \cdot \vec{e}_2 $ unbounded term that might blow up the noise on the ciphertext, and decryption will fail.
Since the error vector $ \vec{e}_2 $ is bounded by an upper bound $ B $, the real problem is that the values in encryption matrix $ C $ is unbounded in $ \mathbb{Z}_q $. Therefore multiplying these unbounded values to a bounded noise vector will give us unbounded noise!
If we can somehow bound the values in $ C $ to be small and still make it perfectly random, then our problem will be easily solved! Namely, we want to make the infinity norm of matrix $ C $ small: $ \mid\mid C \mid\mid_\infty = small $, which means every value in matrix $ C $ is small. However, we also want to maintain the randomness of matrix $ C $, so it’s not too deterministic and destroys the security.
So what’s the secret sauce that’s missing from here? Binary Decomposition to the rescue!
Binary Decomposition
If we have a number $ x \in \mathbb{Z}_q $, the way to reduce its infinity norm while maintaining its original value is to convert it into binary representation. We define: \(\hat{x} = (x_0, x_1, \dots, x_{log(q)-1}) \in \{0, 1\}^{log(q)}\) $ \hat{x} $ is the binary decomposition of the original value $ x $. Namely, a binary decomposition will convert a number in $ \mathbb{Z}_q $ into $ log(q) $ bits, and each bit will only have value $ {0, 1} $. Now, if we look at the infinity norm of $ \hat{x} $, we can see that it’s atmost 1! Therefore it will satisfy our small norm requirement.
The other reason why binary decomposition is the best candidate is because reconstructing $ x $ from the decomposition $ \hat{x} $ can be expressed as a linear transformation. Given $ x_0, \dots, x_{log(q)-1} $, we can efficiently reconstruct: \(x = \sum_{i=0}^{log(q)-1} x_i \cdot 2^i\) Thus, this reconstruction can also be expressed as a matrix.
Next, we extend the notion of binary decomposition to vectors and matrices. For a given vector $ \vec{x} \in \mathbb{Z}_q^n $, the binary decomposition $ \hat{x} $ is basically the decomposition of every single element in $ \vec{x} $. \(\hat{x} = (\underbrace{x_{0,0}, \dots, x_{0, log(q)-1}}_\text{log(q)-1 elements}, x_{1, 0}, \dots, x_{1, log(q)-1}, \dots, x_{n-1, 0}, \dots, x_{n-1, log(q)-1})\) Totally, there will be $ n \times log(q) $ elements in the decomposed vector $ \hat{x} $.
Similarly, for matrix $ C $, we can simply apply the vector binary decomposition to every row in matrix $ C $ to obtain its binary decomposition $ \hat{C} $. \(C = \begin{pmatrix}C_1\\\vdots\\C_m\end{pmatrix} \rightarrow\hat{C} = \begin{pmatrix}\hat{C_1}\\\vdots\\\hat{C_m}\end{pmatrix}\) When we want to reconstruct $ C $ from $ \hat{C} $, we can write the reconstruction linear transformation of every element in $ C $ as a matrix $ G $, such that: \(C = \hat{C} \cdot G\) Where $ G $ is the reconstruction matrix. In some papers, we will also write the linear decomposition as the inverse of the reconstruction matrix $ G^{-1}(\cdot) $, so $ \hat{C} = G^{-1}(C) $.
Now with all the linear decomposition stuff at our disposal, let’s see if we can add this into our FHE construction.

Straw man #3: Add Binary Decomposition (The GSW Scheme)
From the previous section, we know that the term $ C_1 \cdot \vec{e}_2 $ is unbounded and might introduce too much noise. We also learned that by applying binary decomposition $ G^{-1}(\cdot) $ to a matrix, we can efficiently obtain a decomposed matrix $ \hat{C} $ with very small infinity norm.
Now, let’s apply this idea and see if we can improve the last construction a bit better.
KeyGen
$ KeyGen(1^\lambda) $: The key generation process is still the same. We will randomly sample $ \tilde{s} $ and obtain $ \vec{s} \leftarrow \begin{pmatrix}\tilde{s}\-1\end{pmatrix} $. Both $ \tilde{s}, \vec{s} $ are used in the encryption scheme.
Encryption
$ Enc(\tilde{s}, \mu \in {0, 1}) $: The encryption algorithm is pretty much the same as before. We first construct an LWE instance by selecting $ m = n \cdot log(q) $. Then we sample the matrix $ A \stackrel{R}{\leftarrow} \mathbb{Z}_q^{m \times (n-1)} $ as well as the error vector $ \vec{e} \stackrel{R}{\leftarrow} x_B^m $. Then, we will compute the ciphertext $ C $: \(C = (A, A \cdot \tilde{s} + \vec{e}) + \mu \cdot G \in \mathbb{Z}_q^{m \times n}\) Finally, instead of outputting the ciphertext $ C $ directly, we apply our binary decomposition to the ciphertext and output $ \hat{C} \leftarrow G^{-1}(C) $ instead.
Decryption
$ Dec(\vec{s}, \hat{C}) $: In order to decrypt the decomposed ciphertext $ \hat{C} $, first we will apply the reconstruction matrix $ G $, and then we will multiply it by the private key $ \vec{s} $: \(\begin{align*} \hat{C} \cdot G \cdot \vec{s} &= C \cdot \vec{s}\\ &= (A, A \cdot \tilde{s} + \vec{e}) \begin{pmatrix}\tilde{s}\\-1\end{pmatrix} + \mu \cdot G \cdot \vec{s}\\ &= A \cdot \tilde{s} - A \cdot \tilde{s} - \vec{e} + \mu \cdot G \cdot \vec{s}\\ &= \mu \cdot G \cdot \vec{s} - \vec{e} \end{align*}\) Once we obtain the final term, which is a vector of $ m $ elements, we can just look at the first element of this result vector. If the magnitude of the first element is small (say below $ q/4 $), then we output $ \mu = 0 $. Else we output $ \mu = 1 $.
If we expand how we get the first element of the result vector, we can get something like this: \((\mu \cdot G \cdot \vec{s})_1 = \mu \cdot (\vec{G})_1 \cdot \vec{s} = \mu \cdot (1, 0, \dots, 0) \cdot \begin{pmatrix}s_1\\\vdots\\s_{n-1}\\-1 \end{pmatrix} = \mu \cdot s_1\) Notice that the first row of the matrix $ G $ is basically an one-hot vector with 1 as the first term and the rest to be 0. Because $ s_1 $ is simply a random number sampled in $ \mathbb{Z}_q $, it has very high probability to be a large number. Therefore, if $ \mu \cdot s_1 + \vec{e}_1 $ is small, it means that $ \mu $ is 0 with very high probability.
Evaluation
Finally… We are at the point to examine whether our third attempt construction can correctly evaluate addition and multiplication.
Addition is actually pretty easy in this case, because this scheme didn’t change much in the construction. Therefore, we can look at the decryption of an addition evaluation: \(\begin{align*} (\hat{C_1} + \hat{C_2}) \cdot G \cdot \vec{s} &= \hat{C_1} \cdot G \cdot \vec{s} + \hat{C_2} \cdot G \cdot \vec{s}\\ &= \mu_1 \cdot G \cdot \vec{s} - \vec{e}_1 + \mu_2 \cdot G \cdot \vec{s} - \vec{e}_2\\ &= \underbrace{(\mu_1 + \mu_2) \cdot G \cdot \vec{s}}_\text{addition of plaintext} - \underbrace{(\vec{e}_1 + \vec{e}_2)}_\text{small error term} \end{align*}\) Notice that we can get a pretty nice encryption for $ \mu_1 + \mu_2 $ with a small error term $ \vec{e}_1 + \vec{e}_2 $. This is exactly the same as before.
Multiplication is the real deal here. Now let’s see how the decryption of a multiplication evaluation would look like: \(\begin{align*} (\hat{C_1} \cdot \hat{C_2}) \cdot G \cdot \vec{s} &= \hat{C_1} \cdot (\hat{C}_2 \cdot G) \cdot \vec{s}\\ &= \hat{C_1} \cdot C_2 \cdot \vec{s}\\ &= \hat{C_1} \cdot (\mu_2 \cdot G \cdot \vec{s} + \vec{e}_2)\\ &= \mu_2 \cdot \hat{C_1} \cdot G \cdot \vec{s} + \hat{C_1} \cdot \vec{e}_2\\ &= \mu_2 \cdot (\mu_1 \cdot G \cdot \vec{s} + \vec{e}_1) + \hat{C_1} \cdot \vec{e}_2\\ &= \underbrace{(\mu_1 \cdot \mu_2) \cdot G \cdot \vec{s}}_\text{multiplication of pt} + \underbrace{\mu_2 \cdot \vec{e}_1}_\text{small error term} + \underbrace{\hat{C_1} \cdot \vec{e}_2}_\text{relatively small} \end{align*}\) We see that the result is basically the same as the previous construction, except for the fact that now we have the last term as $ \hat{C_1} \cdot \vec{e}2 $. Since $ \hat{C_1} $ is a binary decomposition, the infinity norm is bounded by 1: $ \mid\mid \hat{C_1} \mid\mid\infty \le 1 $. Therefore, the utmost amount of error introduced in this term is $ n \cdot log(p) \cdot B $.
This error bound is not ideal, but at least it’s good enough for us to have some error tolerance. If we choose the right LWE problem instance, then we can get $ L $ steps of multiplication evaluation before this ciphertext reaches its noise threshold.

The diagram above depicts how the noise distribution grows as the circuit goes deeper. Once we reach $ L+1 $ steps of multiplication evaluation, the noise boundaries of 0 and 1 will overlap, and at that point, decryption doesn’t work anymore.
Therefore, this third construction gives us a Leveled Fully Homomorphic Encryption Scheme! This scheme allows us to compute circuits that have utmost $ L $ multiplication gates in series.

Path Forward
Compared to the two previous posts, I must say that this one is much more hardcore and contains lots of mathematical equations and details.
Though I tried my best to make this as simple as possible, it might still confuse some of you. Feel free to read through the three straw man constructions again to consolidate the knowledge of how FHE scheme is constructed from this “approximate eigenvector” method.
If you successfully made it through here and understood most of it, congratulations! You’ve just mastered how FHE works and is built from ground-up. This is really big - considering FHE is still a super new field that hasn’t existed ~10 years ago.
But… What next?
We have together created a Leveled FHE Scheme from the ground up. And this is actually how the GSW Scheme work. (Although GSW Scheme used a public-key variant of the encryption scheme, but the rest is exactly the same.)
The next step is definitely trying to make this LFHE a true FHE! Now we can only evaluate up to $ L $ levels of multiplication. But what if we want to do some encrypted machine learning that might take up to unbounded levels of multiplication?
The key idea to convert an LFHE scheme like GSW to true FHE is Bootstrapping. Bootstrapping is an idea proposed by Gentry that efficiencly “refreshes” the noise of a ciphertext. Basically, if we evaluate multiplication too many times and this ciphertext is approaching its noise boundary, we can apply Bootstrapping to obtain a fresh ciphertext that contains the same plaintext but significantly less noise.
In the next post, let’s take a deep dive into how Bootstrapping works and turn our leveled GSW Scheme into an true FHE.
Credits
Most content of this post were summarized from my notes for CS355. You can locate all the awesome lecture notes from CS355 here.
Thanks again to Dima, Florian, and Saba for teaching this amazing course!